
L’intelligence artificielle transforme profondément les infrastructures informatiques des entreprises. Derrière les promesses d’automatisation, de personnalisation en temps réel ou d’analyse prédictive se cache une réalité technique incontournable : toutes les architectures de calcul ne sont pas conçues pour absorber efficacement les charges massives générées par les modèles d’IA modernes. Les limites des infrastructures traditionnelles apparaissent rapidement lorsque les volumes de données explosent et que les traitements doivent être exécutés en quelques millisecondes.
Dans ce contexte, la comparaison entre CPU et GPU devient centrale. Ces deux types de processeurs répondent à des logiques de calcul radicalement différentes et jouent aujourd’hui des rôles complémentaires dans les data centers modernes. Comprendre leurs spécificités permet non seulement de mieux dimensionner une infrastructure IA, mais aussi d’anticiper les impacts en matière de performance, de consommation énergétique, de refroidissement et de coûts d’exploitation. Avant de choisir une architecture adaptée à ses besoins, il est donc essentiel de comprendre pourquoi les GPU se sont imposés comme les accélérateurs incontournables de l’intelligence artificielle.
Vos priorités pour réussir la transition GPU dans votre data center :
- Évaluer la densité de puissance de vos racks actuels avant tout achat de serveur GPU
- Identifier les charges de travail parallélisables (entraînement, inférence) qui justifient un GPU
- Anticiper les besoins en refroidissement et en bande passante réseau dès la phase de conception
- Choisir entre architecture dédiée, partagée ou hybride selon votre volume de calculs IA
GPU et CPU : deux philosophies de calcul pour l’IA
Prenons une situation classique : une ETI souhaite déployer un moteur de recommandation en temps réel pour son site e-commerce. Son infrastructure CPU, rodée depuis des années pour traiter les commandes et gérer les bases de données, atteint la saturation dès que le modèle d’IA doit analyser des milliers de profils clients simultanément. La raison tient à la nature même des processeurs.
Le CPU excelle dans l’exécution séquentielle de tâches complexes : il enchaîne rapidement des opérations variées, gère les interruptions, coordonne les flux de données. Sa force réside dans la polyvalence et la haute fréquence d’horloge. Un serveur CPU classique dispose de quelques dizaines de cœurs puissants, chacun capable de traiter des instructions différentes. Ce modèle convient parfaitement aux applications métier traditionnelles, aux requêtes SQL, aux traitements transactionnels.
Le GPU, à l’inverse, privilégie le parallélisme massif. Un GPU moderne embarque plusieurs milliers de cœurs plus simples, conçus pour exécuter la même opération sur des millions de données en simultané. Cette architecture trouve toute sa pertinence dans les charges de travail de deep learning, où les calculs matriciels se répètent à l’infini. L’entraînement d’un modèle de vision par ordinateur, par exemple, impose de multiplier et d’additionner des millions de paramètres à chaque itération. Là où un CPU traiterait ces opérations l’une après l’autre, le GPU les distribue instantanément sur ses milliers de cœurs, réduisant drastiquement le temps de calcul.
Les données du marché montrent que cette spécialisation technique se traduit par des gains de performance mesurables. Pour une tâche d’inférence sur des modèles de langage ou de reconnaissance d’images, le passage d’une infrastructure CPU vers une infrastructure intégrant des GPU haute performance, présentés sur ce site, permet souvent de diviser les temps de réponse par un facteur significatif, tout en optimisant la consommation énergétique par transaction. Cette transition exige néanmoins de repenser l’ensemble de la chaîne technique, du stockage au réseau.
Analogie : la brigade de cuisine vs la chaîne de montage
Le CPU ressemble à un chef étoilé capable de préparer un plat complexe du début à la fin, en jonglant entre les techniques. Le GPU, lui, se compare à une usine de conditionnement : des centaines d’ouvriers effectuent chacun la même tâche simple (emballer, étiqueter) à une cadence phénoménale. Pour servir un banquet de mille couverts, la chaîne de montage l’emporte. Pour créer un menu gastronomique sur mesure, le chef reste indispensable.
Cette complémentarité explique pourquoi les architectures hybrides, où CPU et GPU cohabitent, deviennent la norme dans les data centers modernes. Le CPU conserve le pilotage applicatif, la gestion des flux, les requêtes métier classiques. Le GPU prend en charge les calculs IA intensifs, délestant le CPU de charges qu’il n’est pas conçu pour traiter efficacement.
Les trois grands modèles d’architecture pour intégrer des GPU
Face à la nécessité d’intégrer des capacités de calcul IA, trois scénarios d’architecture se distinguent. Chaque modèle répond à des profils d’entreprise et des volumétries de calcul spécifiques. Le choix entre ces options conditionne l’investissement initial, la flexibilité et les coûts d’exploitation sur plusieurs années.
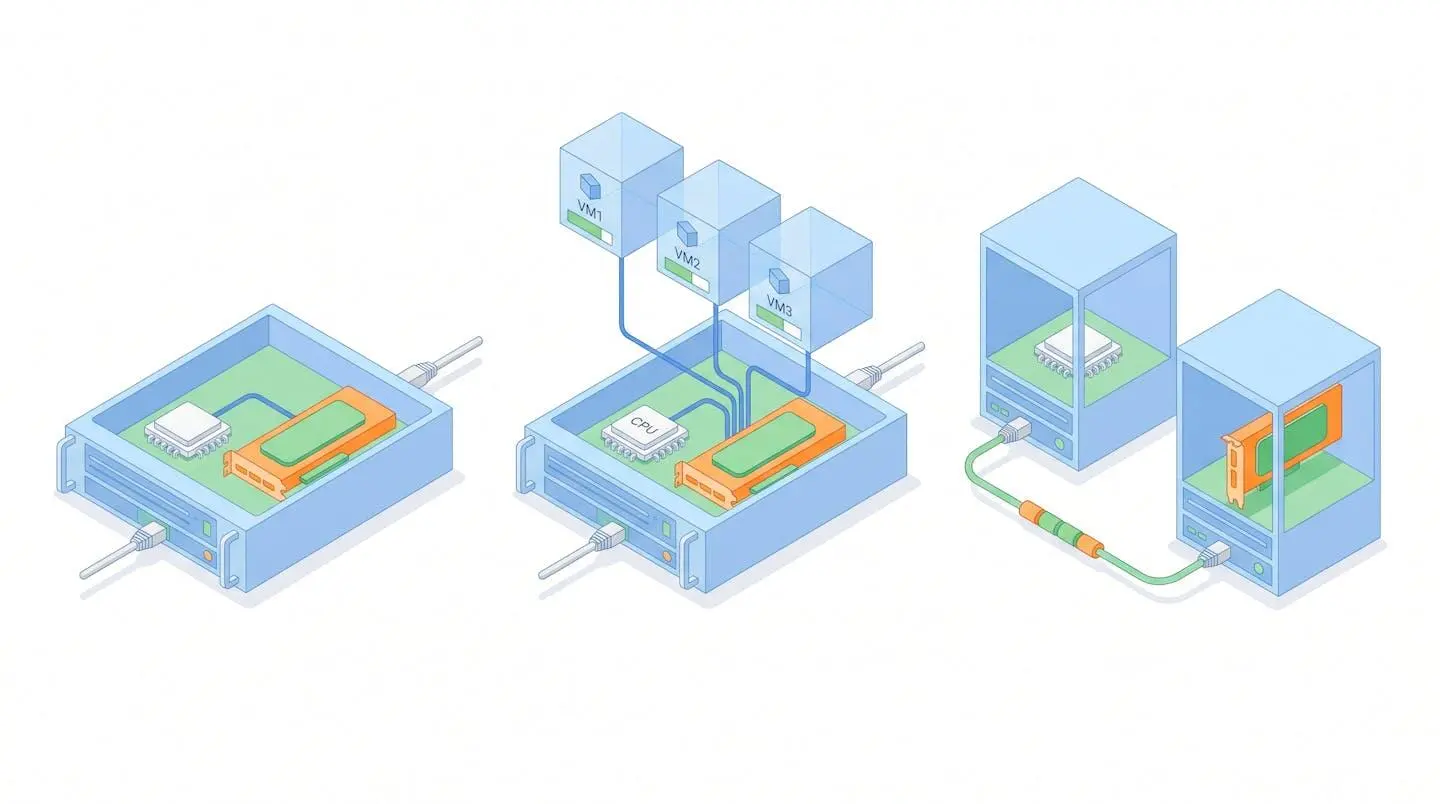
Le serveur GPU dédié consiste à acquérir des machines équipées de cartes graphiques haute performance, installées en rack et dédiées exclusivement aux charges de travail IA. Ce modèle s’adresse aux organisations qui entraînent régulièrement des modèles volumineux ou qui doivent garantir une latence minimale pour l’inférence en production. L’avantage principal réside dans la performance brute et la prévisibilité des ressources. L’inconvénient : un investissement initial élevé et une utilisation parfois sous-optimale si les charges IA ne saturent pas les GPU en permanence.
L’architecture GPU partagée, ou GPU virtualisé, permet de mutualiser une flotte de GPU entre plusieurs équipes ou applications via des technologies de virtualisation (vGPU, MIG). Une startup en phase de R&D, par exemple, peut allouer dynamiquement des fractions de GPU à ses data scientists pour des expérimentations, puis basculer les ressources vers la production durant la journée. Cette approche optimise le taux d’occupation des accélérateurs et réduit les coûts d’infrastructure. Elle nécessite néanmoins une couche logicielle d’orchestration et peut introduire de la latence supplémentaire selon les cas d’usage. Comme le souligne le référentiel méthodologique d’évaluation environnementale des services numériques publié en avril 2025, l’optimisation de l’utilisation des ressources cloud et datacenter devient un enjeu de conformité réglementaire autant que de performance.
Le modèle hybride CPU+GPU repose sur une séparation physique ou logique des charges : les serveurs CPU continuent d’assurer les traitements transactionnels classiques, tandis qu’un cluster GPU dédié prend en charge les opérations d’IA. Cette configuration offre une flexibilité maximale et permet d’étendre progressivement la capacité GPU sans toucher à l’existant. Elle implique toutefois de repenser les flux réseau pour minimiser la latence entre les zones CPU et GPU, et d’investir dans des solutions de stockage capables d’alimenter rapidement les deux environnements. Un guide d’utilisation du cloud peut aider à structurer cette transition en identifiant les services cloud compatibles avec une architecture hybride.
| Modèle | Profil adapté | Avantage clé | Point de vigilance |
|---|---|---|---|
| GPU dédié | Grand compte, entraînement fréquent | Performance maximale, latence minimale | Investissement initial élevé |
| GPU partagé | Startup, R&D, charges variables | Mutualisation, coûts optimisés | Complexité orchestration |
| Hybride CPU+GPU | ETI, migration progressive | Flexibilité, évolution incrémentale | Architecture réseau à repenser |
Dans la pratique, le modèle hybride s’impose fréquemment comme compromis pour les entreprises disposant déjà d’un data center opérationnel. Il autorise une montée en puissance par paliers, sans rupture brutale de l’exploitation, tout en garantissant la compatibilité avec les applications métier existantes.
Adapter son data center existant : les points de vigilance
L’intégration de serveurs GPU dans un environnement conçu pour des CPU classiques soulève des défis techniques concrets. La densité de puissance par rack, la capacité de refroidissement, la bande passante réseau et la cohérence du stockage deviennent des variables critiques à réévaluer avant tout déploiement.

La densité de puissance constitue le premier goulot d’étranglement. Un rack CPU classique consomme 5 à 10 kW. Un rack équipé de serveurs GPU denses peut atteindre 20 à 40 kW, voire davantage pour les configurations haute performance. Si votre infrastructure actuelle ne dispose pas de circuits électriques dimensionnés pour ces valeurs, le déploiement nécessitera des travaux de mise à niveau des onduleurs et des PDU (Power Distribution Units). Selon la proposition de loi sur l’encadrement des data centers déposée en février 2025, les nouvelles installations doivent désormais intégrer des critères de transition énergétique et de consommation d’espace dès la phase de planification.
Le refroidissement suit la même logique d’intensification. Les GPU génèrent une chaleur importante, concentrée sur une surface réduite. Les systèmes de refroidissement par air traditionnel montrent rapidement leurs limites. Pour les clusters GPU de taille conséquente, le refroidissement liquide (direct-to-chip ou immersion) devient une option sérieuse. Cette technologie, autrefois réservée aux supercalculateurs, se démocratise dans les data centers d’entreprise pour maîtriser la température et réduire la consommation des ventilateurs. Un service d’infogérance informatique peut prendre en charge cette transition technique et assurer la maintenance des équipements de refroidissement avancés.
La bande passante réseau représente un autre point de friction. Les charges de travail IA impliquent des transferts de données volumineux : jeux d’images pour la vision, corpus textuels pour le NLP, flux vidéo pour l’analyse temps réel. Une architecture réseau limitée à 1 ou 10 Gbit/s par serveur risque de créer un goulot, annulant les gains de performance apportés par les GPU. Les infrastructures modernes privilégient des interconnexions 25, 50 ou 100 Gbit/s entre les serveurs GPU et le stockage, avec des topologies à faible latence (spine-leaf) pour garantir la fluidité des échanges.
Enfin, la cohérence du stockage mérite une attention particulière. Les GPU consomment les données à une vitesse bien supérieure aux CPU. Un système de stockage SAN ou NAS traditionnel, optimisé pour des accès séquentiels ou transactionnels, peut devenir un frein majeur. Les architectures GPU performantes s’appuient sur du stockage NVMe local ou sur des solutions de stockage distribué haute vitesse (Lustre, GPFS, Ceph) capables de délivrer plusieurs dizaines de Go/s en lecture simultanée.
- Vérifier la capacité électrique disponible par rack (kW) et dimensionner les circuits en conséquence
- Évaluer le système de refroidissement actuel et estimer la température cible pour les GPU
- Mesurer la bande passante réseau entre zones de stockage et serveurs de calcul
- Auditer les performances du stockage pour garantir un débit compatible avec les charges IA
- Lister les applications métier critiques et valider leur compatibilité avec une architecture hybride
Ces vérifications techniques conditionnent la réussite du projet. Elles permettent d’identifier les travaux préparatoires indispensables et d’éviter les mauvaises surprises en phase de production. Parallèlement, les aspects liés à la bonnes pratiques de sécurité informatique doivent être intégrés dès la conception, notamment pour sécuriser les flux de données sensibles entre les environnements CPU et GPU.
Quels indicateurs pour valider votre futur investissement GPU ?
Investir dans une infrastructure GPU représente un engagement financier et technique sur plusieurs années. Pour objectiver cette décision, il convient de bâtir une grille d’évaluation articulée autour de critères mesurables : coût total de possession, performance par watt, retour sur investissement selon les cas d’usage, et risque d’obsolescence.

Le coût total de possession (TCO) dépasse largement le prix d’achat du matériel. Il intègre l’alimentation électrique, le refroidissement, la maintenance, le renouvellement et les licences logicielles (orchestrateurs, frameworks). Les serveurs GPU affichent un investissement initial conséquent, avec des configurations haut de gamme atteignant plusieurs dizaines de milliers d’euros par unité. Cet investissement se justifie si les gains de temps de calcul permettent de réduire la durée des cycles d’innovation, d’améliorer la qualité des modèles IA ou de servir davantage de requêtes simultanées. Une analyse fine du TCO sur trois ans permet de comparer objectivement plusieurs scénarios d’infrastructure.
La performance par watt, ou efficacité énergétique, devient un critère déterminant dans un contexte de hausse des coûts de l’électricité et de réglementation environnementale. Pour une tâche d’inférence donnée, les GPU peuvent offrir un meilleur ratio performance/consommation que les CPU, malgré leur consommation instantanée plus élevée. Les chiffres publiés par la Direction générale des Entreprises montrent que le numérique représente déjà 2,5 % des émissions de la France et 10 % de la consommation électrique nationale. Face à cette réalité, optimiser chaque watt dépensé dans le data center devient un impératif stratégique autant que financier.
Le retour sur investissement (ROI) varie considérablement selon les cas d’usage. Un acteur de la santé qui accélère le diagnostic par imagerie médicale grâce à des modèles de vision entraînés sur GPU mesure son ROI en vies sauvées et en réduction des délais de prise en charge. Un e-commerçant évalue l’impact de son moteur de recommandation IA sur le panier moyen et le taux de conversion. Un industriel quantifie les économies générées par la maintenance prédictive basée sur l’analyse de flux de capteurs. Dans tous les cas, le ROI se construit sur des métriques métier concrètes, pas uniquement sur des gains de performance brute.
- Réduction drastique des temps d’entraînement des modèles IA
- Meilleure efficacité énergétique pour les charges parallélisables
- Capacité à traiter des volumes de données massifs en temps réel
- Évolutivité progressive via architectures hybrides
- Investissement initial élevé et délais d’approvisionnement variables
- Densité de puissance et contraintes de refroidissement accrues
- Nécessité de revoir l’architecture réseau et stockage
- Compétences internes à développer pour l’exploitation
L’analyse finale des projets GPU réussis révèle un point commun : ils s’inscrivent dans une feuille de route claire, portée par la direction et validée par des preuves de concept. Plutôt que d’investir massivement d’emblée, les organisations performantes démarrent par un cluster GPU réduit, mesurent les résultats sur un cas d’usage métier prioritaire, puis étendent progressivement la capacité en fonction des retours terrain.